
A while ago, in one of our larger customer environments, we observed that the Community Catalog was very slow to load. It would take 30 seconds and upwards to fully load. The search was sluggish and incomplete, and the OrientMe Page or “Top Updates” would mostly not load. Furthermore, the Metrics application would not always display the data; the statistics would just be displayed as empty.
Troubleshooting #
Looking at the logs, it quickly became apparent that the Metrics application logs were overfilled with error messages like the following:
Trimmed Error Message from Metrics Logs
[9/18/25 15:25:09:807 CEST] 0000018c Elasticsearch W com.ibm.connections.metrics.elasticsearch.ElasticsearchClient httpRequest ElasticSearch returned - 429 : {“error”:{“root_cause”:[{“type”:“circuit_breaking_exception”,“reason”:"[parent] Data too large, data for [indices:data/read/search[phase/query]] would be [515182106/491.3mb], which is larger than the limit of [510027366/486.3mb], real usage: [515181032/491.3mb], new bytes reserved: [1074/1kb], usages [request=64/64b, fielddata=12796/12.4kb, in_flight_requests=66862/65.2kb]",“bytes_wanted”:515182106,“bytes_limit”:510027366,“durability”:“TRANSIENT”},{“type”:“circuit_breaking_exception”,“reason”:"[parent] Data too large, data for [indices:data/read/search[phase/query]] would be [522981218/498.7mb], which is larger than the limit of [510027366/486.3mb], real usage: [522980144/498.7mb], new bytes reserved: [1074/1kb], usages [request=256/256b, fielddata=23212/22.6kb, in_flight_requests=1074/1kb]",“bytes_wanted”:522981218,“bytes_limit”:510027366,“durability”:“PERMANENT”},{“type”:“circuit_breaking_exception”,“reason”:"[parent] Data too large, data for [indices:data/read/search[phase/query]] would be [532587482/507.9mb], which is larger than the limit of [510027366/486.3mb], real usage: [532586408/507.9mb], new bytes reserved: [1074/1kb], usages [request=256/256b, fielddata=16776/16.3kb, in_flight_requests=33954/33.1kb]",“bytes_wanted”:532587482,“bytes_limit”:510027366,“durability”:“PERMANENT”},{“type”:“circuit_breaking_exception”,“reason”:"[parent] Data too large, data for [indices:data/read/search[phase/query]] would be [516230682/492.3mb], which is larger than the limit of [510027366/486.3mb], real usage: [516229608/492.3mb], new bytes reserved: [1074/1kb], usages [request=64/64b, fielddata=12796/12.4kb,
After a brief discussion with Christoph Stoettner (aka Stoeps) over the error message and the behavior of the applications, he suggested to check and increase the RAM as well as the JVM Memory allocation of the OpenSearch Pods. And sure enough, looking at the logs of the OpenSearch Data pods (for example opensearch-cluster-data-0), we could observe the following warning messages suggesting that the JVM JAVA Heap Memory must be increased.
[2025-09-30T11:15:31,043][INFO ][o.o.i.b.HierarchyCircuitBreakerService] [opensearch-cluster-data-1] attempting to trigger G1GC due to high heap usage [531145496]
[2025-09-30T11:15:31,046][INFO ][o.o.i.b.HierarchyCircuitBreakerService] [opensearch-cluster-data-1] GC did not bring memory usage down, before [531145496], after [532229160], allocations [1], duration [3]
Furthermore, looking at the OpenShift metrics data (yes, the HCL Connections Component Pack runs on OpenShift in this environment), I could see that the opensearch-cluster-master ods were constantly hitting the default specified memory threshold of 1GB.
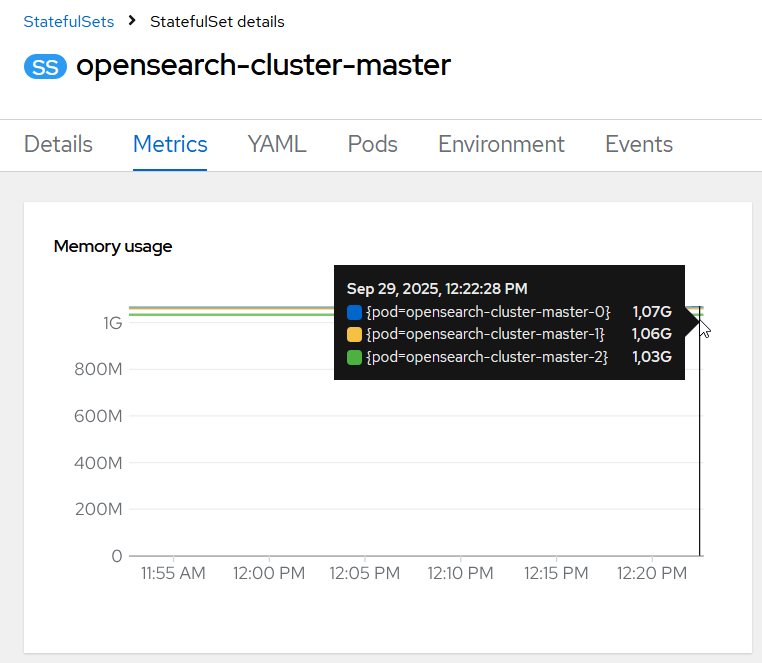
The opensearch-cluster-data pods were using slightly less memory than defined via the threshold, but that was soon to change…
Solution #
In order to solve the issue, we’ve started with modifying the memory and jvm heap size limits of the opensearch-cluster-master StatefulSet.
The default memory limit is 1GB and the jvm was set to -Xmx512M -Xms512M. We decided to quadruple those values. This can be done “on the fly” by editing the configuration of the StatefulSet. To do so, you can use the following commands:
OpenShift: oc edit statefulset opensearch-cluster-master
K8s: kubectl edit statefulset opensearch-cluster-master
After issuing one of the commands above, you will be presented with the YAML file in which the configuration of the StatefulSet is defined. In which I have modified the following parameters:
containers:
- resources:
limits:
cpu: '1'
memory: 4Gi
---
- name: OPENSEARCH_JAVA_OPTS
value: '-Xmx2048M -Xms2048M'
After saving the modified configuration file, the opensearch-cluster-master pods will automatically restart. If you have deployed multiple pods, they will restart one-by-one, so there is no complete service outage.
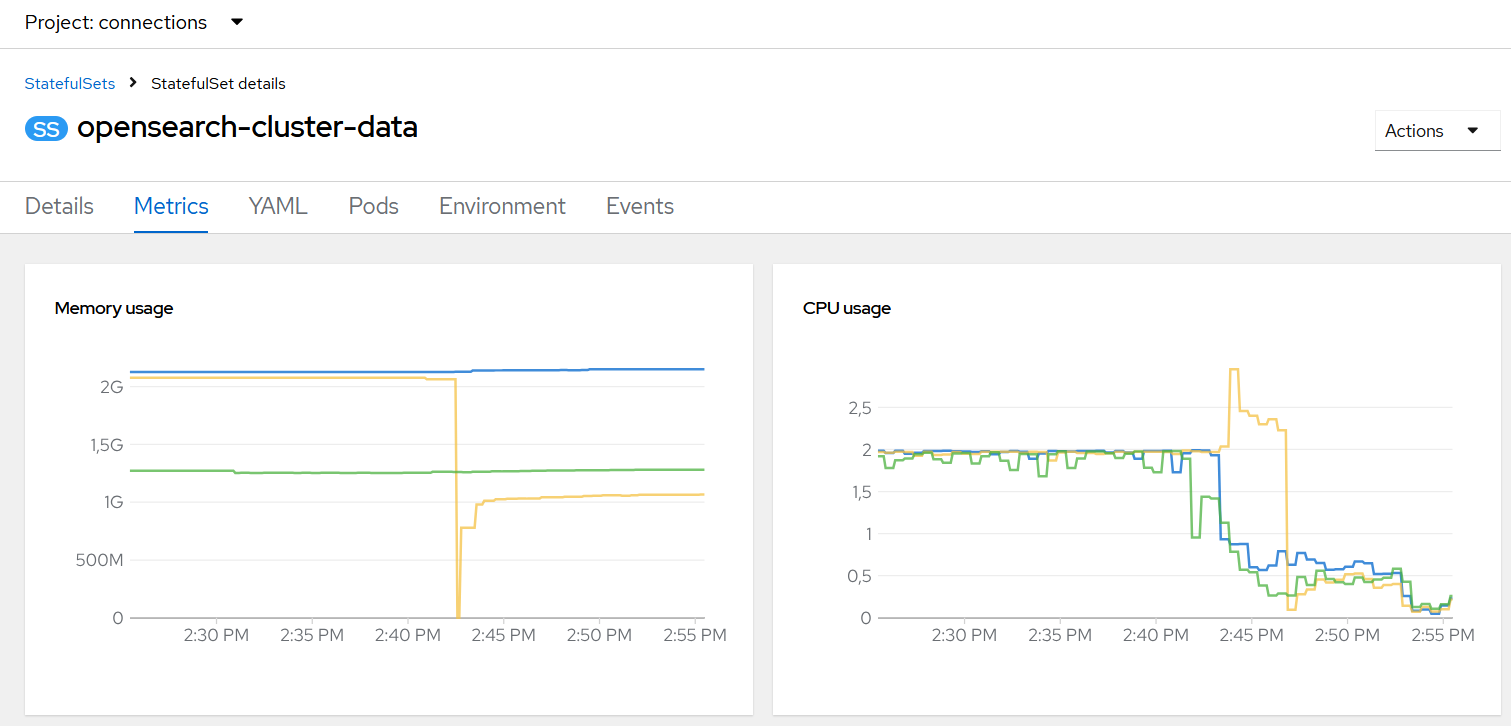
After all opensearch-cluster-master pods had restarted, we observed that the opensearch-cluster-data pods have hit the memory threshold, and the error in the Connections Metrics Application was still occurring, although we could see an improvement in the behavior of the HCL Connections applications. Therefore, we’ve decided to repeat the same process for the opensearch-cluster-data pods and quadruple the memory and Java heap size limits by issuing the following commands:
OpenShift: oc edit statefulset opensearch-cluster-data
K8s: kubectl edit statefulset opensearch-cluster-data
And modifying the configuration like the following:
containers:
- resources:
limits:
cpu: '2'
memory: 8Gi
---
- name: OPENSEARCH_JAVA_OPTS
value: '-Xmx2048M -Xms2048M'
After the modified configuration was saved and the pods restarted, the error messages from the HCL Connections Metrics logs would not appear anymore. Interestingly, we observed that the CPU of the opensearch-cluster-data pods has “ramped-up” and was hitting the limit for about 30 minutes after the restart.
Making the Solution Persistent #
After the issue was successfully resolved, we wanted to make those configuration changes persistent after HCL Connections Component Pack updates. We have achieved that by modifying the yaml files we have been using for the installation of OpenSearch Data and Master pods:
opensearch-master.yaml
resources:
limits:
cpu: "1"
memory: "4Gi"
requests:
cpu: "0.1"
memory: "768Mi"
opensearchJavaOpts: "-Xmx2048M -Xms2048M"
opensearch-data.yaml
resources:
limits:
cpu: "2"
memory: "8Gi"
requests:
cpu: "0.5"
memory: "3072Mi"
opensearchJavaOpts: "-Xmx2048M -Xms2048M"
Further testing showed that the modified and added parameters in the YAML files specified above would persist after the upgrade of the HCL Connections Component Pack.
Conclusion #
This showed us that after installing the HCL Connections Component Pack and switching to OpenSearch for search and metrics operations, the same becomes vital for the operation of HCL Connections. I hope this saves you some headaches.